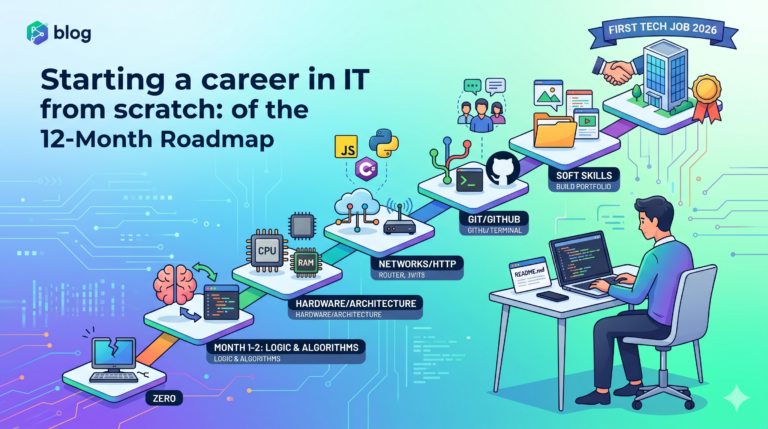
Objetivo: Capacitar o iniciante a entender, modelar e manipular dados utilizando SQL de forma profissional.
Você já parou para pensar no que acontece no exato milissegundo em que você clica em “comprar” ou dá um “like” em uma foto? Enquanto a interface brilha na sua tela e as animações tentam te encantar, nos bastidores da aplicação, um titã silencioso está trabalhando sob pressão extrema para garantir que essa informação não se perca no vácuo digital. O banco de dados é a memória viva e a “única fonte da verdade” de qualquer sistema moderno; sem ele, até a aplicação mais sofisticada do mundo não passaria de uma casca vazia e esquecida, incapaz de reconhecer quem você é ou o que você fez há cinco segundos.
No caminho para o seu primeiro emprego tech em 2026, dominar o SQL é como ganhar um passe de bastidores para a engenharia de software de elite. Enquanto a maioria dos iniciantes se distrai com o brilho passageiro de frameworks que mudam a cada estação, o profissional que entende a persistência de dados constrói uma vantagem competitiva inabalável: a capacidade de estruturar o caos e gerenciar o ativo mais valioso da nossa era. Prepare-se para um mergulho profundo que vai muito além de comandos básicos; este guia é o manual de arquitetura que transformará você em um desenvolvedor indispensável, capaz de projetar sistemas que não apenas funcionam, mas que suportam o peso do mundo real.
Bancos de Dados e SQL: O Coração da Persistência de Informação
No cenário tecnológico de 2026, o dado é o ativo mais valioso de qualquer organização. De sistemas simples de e-commerce a algoritmos complexos de Inteligência Artificial, tudo depende da capacidade de armazenar, recuperar e manipular informações de forma eficiente e segura. Se você está no subnicho Rumo ao primeiro emprego Tech, entender de bancos de dados não é um “extra”; é o alicerce fundamental.
Muitos iniciantes focam excessivamente na linguagem de programação (Python, Java, JavaScript) e tratam o banco de dados como uma “caixa preta” onde as informações são guardadas. Este é um erro estratégico. Um desenvolvedor que entende de SQL (Structured Query Language) e modelagem relacional é capaz de desenhar sistemas mais rápidos, baratos e escaláveis.
Neste guia, vamos explorar desde a teoria dos conjuntos que fundamenta o modelo relacional até as técnicas avançadas de otimização de consultas que farão você brilhar em qualquer teste técnico.
1. O que é um Banco de Dados? Da Ficha ao Digital
Antes da computação moderna, as empresas utilizavam arquivos físicos e fichas para organizar informações. O problema era a redundância e a dificuldade de acesso. Um Sistema de Gerenciamento de Banco de Dados (SGBD) é o software que permite que programas e usuários interajam com os dados de maneira estruturada.
A Diferença entre Dados e Informação
É crucial entender que Dado é apenas um fato bruto (ex: o número “42”), enquanto Informação é o dado contextualizado e processado (ex: “42 é a idade do cliente”). O banco de dados serve para transformar coleções massivas de dados em informações úteis para o negócio.
Por que não usar apenas planilhas Excel?
Iniciantes frequentemente perguntam por que precisamos de SQL se o Excel já organiza dados em tabelas. A resposta reside em três pilares:
-
Relacionamentos: SQL lida de forma nativa com a conexão entre milhões de registros.
-
Segurança e Concorrência: Milhares de usuários podem ler e escrever no banco simultaneamente sem corromper os arquivos.
-
Volume: Bancos de Dados Relacionais lidam com Terabytes de dados, algo que travaria qualquer planilha convencional.
2. O Modelo Relacional e a Teoria dos Conjuntos
A grande maioria dos bancos de dados do mercado (PostgreSQL, MySQL, Oracle, SQL Server) segue o Modelo Relacional, proposto por Edgar F. Codd em 1970. Este modelo baseia-se na ideia de que os dados devem ser organizados em Relações (que chamamos popularmente de Tabelas).
Entidades e Atributos
-
Entidade: É o objeto do mundo real que queremos representar (ex: Cliente, Produto, Pedido).
-
Atributo: São as características daquela entidade (ex: Nome do Cliente, Preço do Produto, Data do Pedido).
No SQL, uma Entidade torna-se uma Tabela, e os Atributos tornam-se as Colunas. Cada registro individual é chamado de Tupla ou Linha.
3. Modelagem de Dados: A Arte de Estruturar
O maior erro de um desenvolvedor júnior é começar a criar tabelas sem planejar. A modelagem de dados é a etapa de engenharia onde decidimos como os dados se conectam.
Chaves Primárias (Primary Keys) e Estrangeiras (Foreign Keys)
Para que uma tabela seja relacional, cada linha deve ser única.
-
Primary Key (PK): Um identificador único para o registro (ex: ID_Cliente). Ela não pode ser nula nem repetida.
-
Foreign Key (FK): É o que cria o “relacionamento”. É uma coluna em uma tabela que aponta para a PK de outra tabela (ex: a coluna ID_Cliente dentro da tabela Pedidos).
Cardinalidade de Relacionamentos
-
Um para Um (1:1): Um registro na Tabela A relaciona-se com apenas um na Tabela B (ex: Usuário e seu Perfil).
-
Um para Muitos (1:N): Um registro na Tabela A pode ter vários na Tabela B (ex: Um Cliente pode ter vários Pedidos). Este é o tipo mais comum.
-
Muitos para Muitos (N:N): Vários registros em A relacionam-se com vários em B (ex: Vários Alunos em várias Disciplinas). Neste caso, precisamos de uma “Tabela Intermediária” ou “Tabela de Ligação”.
4. Normalização de Dados: Organizando o Caos
A normalização é uma técnica para evitar a redundância e inconsistência de dados. Um desenvolvedor competente conhece as Formas Normais (FN):
-
1ª FN: Eliminar grupos repetidos e garantir que cada coluna contenha apenas um valor atômico.
-
2ª FN: Garantir que todos os atributos dependam da chave primária inteira (evitar dependência parcial).
-
3ª FN: Eliminar dependências transitivas (um campo não deve depender de outro campo que não seja a chave).
Dica de Carreira: Em entrevistas para o primeiro emprego, saber explicar a 3ª Forma Normal demonstra que você não é apenas um “digitador de código”, mas alguém que entende de arquitetura de software.
5. Linguagem SQL: O Padrão Universal
SQL é uma linguagem declarativa. Isso significa que você diz ao computador o que você quer, e não como ele deve fazer. Ela é dividida em quatro subgrupos principais:
Tabela: Categorias da Linguagem SQL
| Categoria | Sigla | Comandos Principais | Objetivo |
| Data Definition Language | DDL | CREATE, ALTER, DROP |
Criar e modificar a estrutura do banco (tabelas, colunas). |
| Data Manipulation Language | DML | INSERT, UPDATE, DELETE |
Adicionar, alterar ou remover os dados dentro das tabelas. |
| Data Query Language | DQL | SELECT |
Consultar e recuperar informações do banco. |
| Data Control Language | DCL | GRANT, REVOKE |
Gerenciar permissões de acesso e segurança. |
6. Dominando o CRUD no SQL
CRUD é o acrônimo para Create, Read, Update e Delete. É a base de qualquer sistema web.
SELECT: A Arte da Consulta
O comando SELECT é o mais utilizado. Ele permite filtrar e transformar dados:
SELECT nome, email
FROM clientes
WHERE status = 'ativo'
ORDER BY data_cadastro DESC;
Aqui, estamos selecionando colunas específicas, filtrando apenas clientes ativos e ordenando pelos mais recentes.
INSERT, UPDATE e DELETE
-
INSERT: Adiciona novos dados.
-
UPDATE: Modifica dados existentes. Cuidado: Nunca esqueça o
WHERE, ou você alterará todos os registros da tabela! -
DELETE: Remove dados. O mesmo cuidado com o
WHEREse aplica aqui. No mercado profissional, costumamos usar o “Soft Delete” (apenas marcar como inativo) em vez de excluir fisicamente o dado.
7. Joins: O Segredo da Relacionalidade
É impossível trabalhar profissionalmente sem dominar os JOINs. Eles servem para combinar dados de duas ou mais tabelas em um único resultado.
-
INNER JOIN: Retorna apenas os registros que possuem correspondência em ambas as tabelas (ex: Clientes que têm Pedidos).
-
LEFT JOIN: Retorna todos os registros da tabela da esquerda e os correspondentes da direita. Se não houver correspondência, retorna NULL (ex: Todos os Clientes, mesmo os que nunca fizeram um pedido).
-
RIGHT JOIN: O oposto do Left Join.
-
FULL JOIN: Retorna tudo de ambos os lados, com NULL onde não houver par.
8. Agregação e Funções de Grupo
Muitas vezes, o negócio precisa de métricas, não de linhas individuais. Para isso, usamos funções de agregação:
-
COUNT(): Conta o número de registros. -
SUM(): Soma valores de uma coluna. -
AVG(): Calcula a média. -
MAX()eMIN(): Encontram os valores extremos.
Para usar essas funções dividindo os dados por categorias, utilizamos o GROUP BY. Exemplo: “Qual o faturamento total por categoria de produto?”.
9. Transações e a Propriedade ACID
Imagine um sistema bancário. Se você transfere dinheiro, o banco precisa tirar de uma conta e colocar na outra. Se o sistema cair no meio do processo, o dinheiro não pode sumir. Para isso, usamos Transações.
Um SGBD profissional deve garantir as propriedades ACID:
-
Atomicidade: Ou a transação acontece inteira, ou nada acontece.
-
Consistência: O banco deve sair de um estado válido para outro estado válido.
-
Isolamento: Uma transação não pode interferir em outra que esteja ocorrendo simultaneamente.
-
Durabilidade: Uma vez que o dado foi salvo, ele não será perdido, mesmo em caso de falha de energia.
10. Performance: Índices e Planos de Execução
No subnicho de alto nível, não basta que a query funcione; ela deve ser rápida. Quando uma tabela tem milhões de linhas, o banco de dados levaria muito tempo para ler tudo. Para resolver isso, usamos Índices.
Pense no índice como o sumário de um livro técnico. Em vez de ler o livro todo para achar um tema, você vai direto na página indicada. Criar índices nas colunas usadas no WHERE e nos JOINs é o que garante que seu sistema suporte o crescimento de usuários.
11. SGBDs Populares: Qual escolher para começar?
Embora o SQL seja um padrão, cada software tem suas particularidades (dialetos).
-
PostgreSQL: O favorito dos desenvolvedores seniores e de startups de tecnologia. É robusto, open-source e extremamente poderoso.
-
MySQL/MariaDB: O mais popular para a web tradicional (WordPress utiliza MySQL). É simples e rápido para leitura.
-
SQLite: Um banco que não precisa de servidor. É ideal para aplicativos mobile e pequenos projetos de estudo.
-
SQL Server: Muito comum em ambientes corporativos e integração com a plataforma .NET da Microsoft.
12. O Roadmap de Estudo para Banco de Dados
Para conquistar o seu primeiro emprego tech, não tente aprender tudo de uma vez. Siga este plano de 4 semanas:
-
Semana 1: Teoria relacional e instalação do PostgreSQL. Aprenda a criar tabelas (
CREATE) e inserir dados (INSERT). -
Semana 2: Consultas básicas com
SELECT. Domine filtros (WHERE), ordenação e limites. Isso é a base do SQL, até mesmo quem não vai trabalhar com SQL diariamente, precisa dominar isso. -
Semana 3: Relacionamentos e Joins. Esta é a parte mais difícil; dedique tempo extra para praticar INNER e LEFT JOIN. Esse aprendizado diferencia um nível raso de quem sabe realmente utilizar o SQL como ferramenta para criar relações em banco de dados.
-
Semana 4: Agregações (
GROUP BY) e Subqueries. Tente resolver problemas de lógica de negócio usando SQL puro. Esses problemas envolverão agregações para que você entenda como o mercado realmente utiliza SQL
Conclusão: O SQL como Diferencial Competitivo
Dominar Bancos de Dados e SQL é o que transforma você em um desenvolvedor completo (Full Stack ou Back-end). Enquanto muitos juniores tremem ao ver uma modelagem de dados complexa, você terá a clareza para entender como o fluxo de informação sustenta a aplicação.
No subnicho “Rumo ao primeiro emprego Tech”, a competência em SQL é uma garantia de estabilidade. As linguagens de programação e frameworks mudam drasticamente a cada 5 anos, mas o SQL permanece o mesmo há décadas. Investir tempo aqui é construir um patrimônio técnico para toda a sua carreira.
Checklist de Prática Imediata:
-
Instale o DBeaver (ferramenta universal para bancos de dados).
-
Crie um banco de dados para um projeto pessoal (ex: um controle de finanças).
-
Tente escrever consultas complexas sem usar a ajuda de IAs num primeiro momento, para fortalecer sua memória muscular lógica.
-
Entenda como o banco se conecta com a sua linguagem de programação favorita.
A jornada do zero ao profissional é feita de camadas. Hoje, você adicionou a camada mais sólida de todas: a persistência. Continue estudando, pratique a modelagem e logo você estará pronto para arquitetar sistemas que movem o mundo.